1. OOP和GP OOP(Object-Oriented programming)和GP(Generic Programming)面向对象编程和通用编程
OOP的目标是将数据和方法整合到一个类中
GP的目标是将数据和方法分开,容器包含了数据,算法包括排序方法等,而他们通过迭代器连接
例:sort()函数需要传入支持随机访问的迭代器,所以sort()不能对list的迭代器进行排序(但list自身有sort函数)
2. 模板
1 2 3 4 5 6 7 8 #define __STL_TEMPLATE_NULL template<> template <class Key > struct hash {}; __STL_TEMPLATE_NULL struct hash <char > { size_t operator () (char x) const return x;} __STL_TEMPLATE_NULL struct hash <short > { size_t operator () (char short ) const return x;}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <class T , class Alloc = alloc> class vector {};template <class Alloc > class vector <bool , Alloc> {};template <class Iterator >struct iterator_traits {};template <class T > sturct iterator_traits<T*> {}; template <class T > sturct iterator_traits<const T*> {};
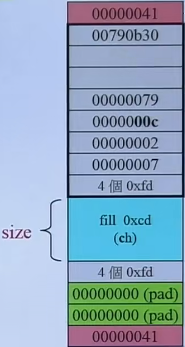
3. 分配器 operator new()操作符根据类对象进行malloc()操作,申请一块内存,结构如图所示,它会包含必须的内存空间以及一些额外的空间存储数据
在VC6中,allocator只是调用了operator new和operator delete这两个操作符来完成allocate和deallocate这两个函数,没有任何特殊设计。这里存在一个问题,如果每次申请的都是1个int变量,因为调用operator new会申请额外空间存储一些必要数据,这会导致存储的额外开销非常大。
1 2 3 4 5 6 7 8 9 10 11 class allocator {public : typedef _SIZT size_type; typedef _PDEF difference_type; typedef _Ty _FARQ *pointer; typedef _Ty value_type; pointer allocate (size_type _N, const void *) {return (_Allocate((difference_type) _N, (pointer)0 )); } void deallocate (void _FARQ *_P, size_type) { operator delete (_P) };
直接使用 allocator 非常反人性,需要传入需要的类型以及数量,清除内存的时候也需要传入对应正确的数量
1 2 3 int *p = allocator <int >().allocate (512 , (int *)0 );allocate <int >().deallocate (p, 512 );
在 G2.9 中也实现了allocator分配器,但实际实际上没有使用,而是使用了alloc分配器。allocator分配器每次申请一个元素时,在该块内存空间还有额外的内存记录该元素的大小等信息。但在容器中,这些信息实际上是非必要的。例如vector容器中所有的元素都是8个字节,不需要为每个元素单独开辟内存空间来记录。alloc从这一点着手进行了优化
1 2 3 4 5 6 template <class T , class Alloc = alloc>class vector {};template <class T , class Alloc = alloc>class list {};
alloc实现在<stl_alloc.h>中,有16条链,每个链负责8字节。例如8字节的int全部放到第0条链中,而alloc每次申请一大块内存来存储这些数据,减少了额外内存空间的使用
在新版的 G4.9 中默认的alloc又恢复成了基本的allocator,而alloc这个分配器被移动到了extension allocators,并且名字修改为了__pool_alloc,所以如果想要使用这个分配器,需要额外进行显示的说明
1 vector<string, __gnu_cxx::__pool_alloc<string>> myVec;
4. 迭代器作用与设计 4.1 Iterator iterator是算法和容器间的桥梁,它让算法知道元素处理的范围,同时也需要满足算法需要的性质(如随机访问,++操作等)。即算法向迭代器提问,迭代器需要有回答的能力,标准规定迭代器必须有下面5种必须的能力
1 2 3 4 5 6 7 8 9 10 template <typename _Tp>struct _List_iterator { typedef std::bidirectional_iterator_tag iterator_category; typedef _Tp value_type; typedef _Tp* pointer; typedef _Tp& reference; typedef ptrdiff_t difference_type; };
1 2 3 4 5 struct input_iterator tag {};struct output_iterator tag {};struct forward_iterator tag : public input_iterator_tag {};struct bidirectional_iterator tag : public forward_iterator_tag (}; struct random_access_iterator tag : public bidirectional_iterator_tag {};
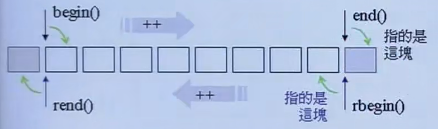
注意迭代器begin()指向第一个元素,end()指向最后一个元素。迭代器rbegin()和rend()实现比较巧妙
1 2 3 4 5 6 7 reverse_iterator rbegin () { return reverse_iterator (end ()); } reverse_iterator rend () { return reverse_iterator (begin ()); }
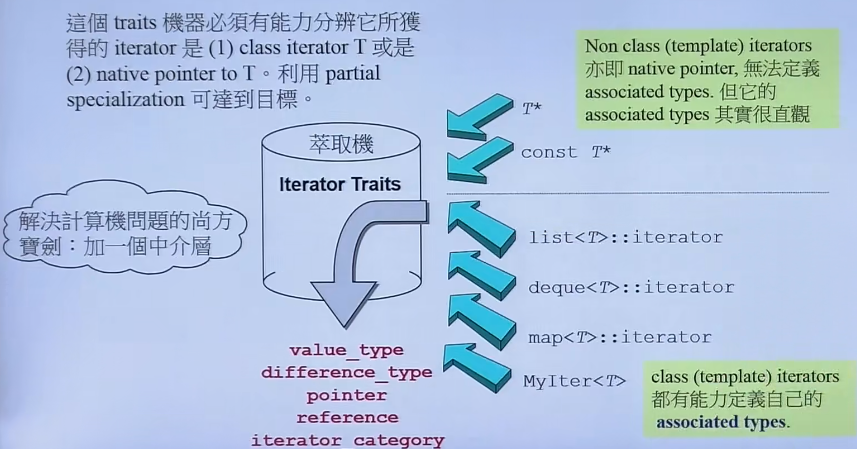
4.2 Iterator Traits 理想情况下iterator应该具备以上5种能力,实际应用中,最基本的指针也是一种退化的迭代器,他不是一个类,没办法描述自己的能力,所以有必要提出一种概念:**Iterator Traits**迭代器的萃取器,来描述该指针具有的迭代器的特征。
在初始的情况下,算法直接调用传入的类来询问它具有哪些能力,但如果传入的是一个普通的指针就会失效。这里引入一个中间层来解决该问题,该中间层就是Iterator Traits。算法通过询问中间层来获取这些信息,这也是一种编程思想。
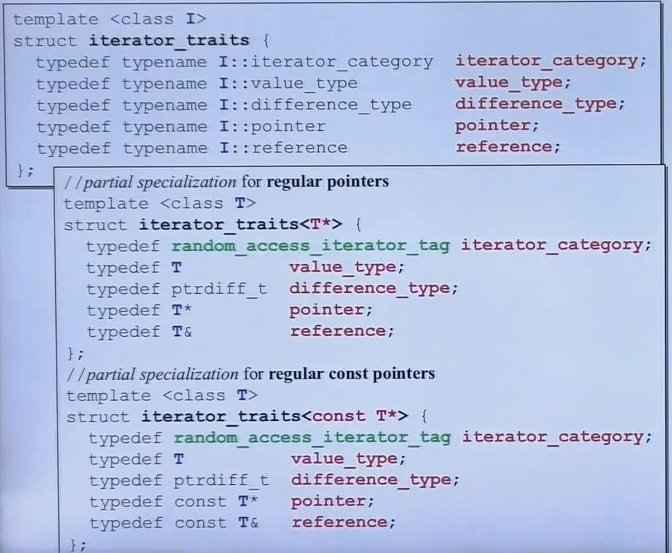
具体实现中非常巧妙的利用了偏特化的特性。首先看下图最下方的代码,算法调用iterator_traits并传入I来询问该迭代器对应的变量类型是什么。
如果I是一个iterator类,则会调用第1种全泛化的方法,并且返回该iterator中的类型
如果I是一个指针,则会进入第2种偏特化的方法,然后返回这个指针的类型
如果I是一个const指针,则进入第3种偏特化方法,这样算法中拿到的类型才不会是一个 const T 类型,否则就没办法操作这些值了
下图展现了完整的 iterator traits
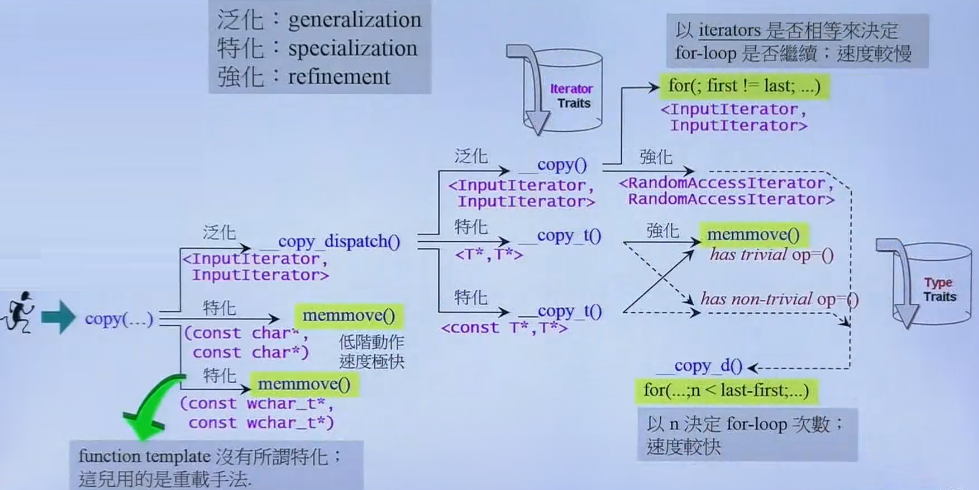
4.3 iterator_category 分类对算法的影响 4.3.1 distance STL中计算distance利用了函数重载的特性。__distance返回两个指针间的距离,通过第三个参数可以实现函数重载
如果该迭代器支持随机访问,则第三个参数category()会实例化一个右值,并且是random_access_iterator_tag类型,此时编译器会调用第二个重载方法
如果该迭代器不支持随机访问,则第三个参数是普通的input_iterator_tag类型,此时调用第一个重载方法,一点一点移动指针计算距离
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 template <class InputIterator >inline iterator_traits<InputIterator>::difference_type__distance(InputIterator first, InputIterator last, input_iterator_tag){ iterator_traits<InputIterator>::difference_type n=0 ; while (first!=last) { ++first; ++n;} return n; } template <class RandomAccessIterator >inline iterator_traits<RandomAccessIterator>::difference_type__distance(RandomAccessIterator first, RandomAccessIterator last, random_access_iterator_tag){ return last-first; } template <class InputIterator >inline iterator_traits<InputIterator>::difference_type distance (InputIterator first, InputIterator last) typedef typename iterator_traits<InputIterator>::iterator_category category; return __distance(first, last, category ()): }
4.3.2 copy copy函数,给定来源的起点和终点,并给定目标就可以实现复制,但实际上内部实现非常复杂
如果传入的迭代器类型是字符指针,则执行memmove()函数进行拷贝,速度很快
否则进入泛化的函数__copy_dispatch()
如果是指针类型的迭代器,则执行__copy_t()
如果拷贝指针时需要调用拷贝构造器单独处理(重写了复制构造函数)
如果不需要调用拷贝构造器则直接调用memmove()
否则进入泛化的函数__copy()
如果是普通的迭代器,则以iterator是否相等来判断是否到迭代器终点,速度较慢
如果是随机访问迭代器,则用循环次数判断是否循环结束,速度快一些
1 2 3 4 5 6 7 8 template <class InputIterator, class OutputIterator>OutputIterator copy (InputIterator first, InputIterator last, OutputIterator result) { while (first!=last){ *result = *first; ++result; ++first; } return result; }
4.3.3 源码对迭代器的暗示 在算法中,由于是模板函数,所以写代码的时候编译器不会报错,但是编译中因为底层需要某种迭代器的功能来完成这个函数,所以编译到这一步时会出现问题。算法源码中会对这些迭代器用命名的方式进行暗示。例如下面暗示了需要容器有随机访问迭代器或前向迭代器
1 2 3 4 5 6 7 8 9 10 11 12 template <class RandomAccessIterator>inline void sort (RandomAccessIterator first, RandomAccessIterator last) if (first!=last){ __Introsort_loop(first, last, value_type (first), __lg(last - first)*2 ); __final_insertion_sort(first, last); } } template <class ForwardIterator>inline void rotate (ForwardIterator first, ForwardIterator middle, ForwardIterator last) if (first == middle || middle == last) return ; __rotate(first, middle, last, distance_type (first), iterator_category (first)); }
4.3.4 STL中的算法 STL中所有的算法都是如下类型,前两个参数提供迭代器
1 2 3 4 template <typename Iterator>std::Algorithm (Iterator itr1, Iterator itr2, ...) }
STL中提供的算法一般都有两种重载,一种是普通的调用,另一种提供给用户自定义的处理方式。可以自定一个函数或者函数对象传入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <class InputIterator, class T>T accumulate (InputIterator first, InputIterator last, T init) for (; first!=last; ++first) init = init + *first; return init; } template <class InputIterator, class T, class BinaryOperation>T accumulate (InputIterator first, InputIterator last, T init, BinaryOperation binary_op) for (; first!=last; ++first) init = binary_op (init, *first); return init; }
5.仿函数和适配器 5.1 仿函数functors 4.3.4小节中提到了算法允许用户自定义处理方式,自定义函数或函数对象(仿函数)传入
注意标准库提供的仿函数都继承了一个父类,而我们自己写的仿函数没有继承,没有继承实际上就没有融入STL的体系结构
1 2 3 4 5 6 7 8 9 10 template <class T >struct plus : public binary_function<T, T, T> { T operator () (const T&x, cont T&y) const {return x+y;}} struct equal_to : public binary_function<T, T, bool >{ bool operator () (const T&x, const T&y) const {return x==y;}}
标准库提供了两个仿函数的可适配(adaptable)条件,STL规定所有的可适配函数都应该继承其中之一。下面一节介绍了为什么适配器必须能够回答这些问题,因为有些函数会向仿函数提出问题,这和萃取器非常类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 template <class Arg , class Result >struct unary_function { typedef Arg argument_type; typedef Result result_type; } template <class Arg1 , class Arg2 , class Result >struct binary_function { typedef Arg1 first_argument_type; typedef Arg2 second_argument_type; typedef Result result_type; }
5.2 适配器Adapters 仿函数适配器的例子。count_if函数会调用第三个仿函数并传入迭代器当前指针的位置,但是less函数需要传入两个值并返回bool值,在这里count_if的调用只能传入一个值,可以使用函数适配器bind2nd来完成这个想法,bind2nd函数对象实际上包装了less函数对象,它需要传入一个函数对象(包含括号重载的处理逻辑),以及第二个值。
它将less函数对象保存到自己的字段中,并在每次调用bind2nd函数对象时,第一个参数是count_if传入的当前迭代器位置,而第二个位置是bind2nd初始化时传入的第二个参数,这样实现了在count_if中调用两个参数的函数对象
这期间,都是通过适配器完成的这一系列操作。bind2nd需要去问函数对象它的第二个参数类型是什么,binder2nd需要去问函数对象它的第返回值类型是什么,这些都是需要适配器完成的。并且在bind2nd函数对象创建binder2nd函数对象时,由于存在强制类型转换,实际上编译器会进行一些检查,如果这里不能转换就会编译失败。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 int main () vector<int > vi = { 40 , 50 , 20 , 11 , 23 , 88 , 99 }; cout << count_if (vi.begin (), vi.end (), bind2nd (less <int >(), 40 ); } for (; _UFirst != _ULast; ++_UFirst) { if (_Pred(*_UFirst)) { ++_Count; } } template <class Operation, class T>inline binder2nd<Operation> bind2nd (const Operation& op, const T&x) { typedef typename Operation::second_argument_type arg2_type; return binder2nd <Operation>(op, arg2_type (x)); } template <class Operation>class binder2nd : public unary_function<typename Operation::first_argument, typename Operation::result_tpye> { ·protected : Operation op; typename Operation::second_argument_type value; public : binder2nd (const Operation& x, const typename Operation::second_argument_type& y) : op (x), value (y) {} typename Operation::result_type operator () (const typename OPeration::first_argument_type &x) const { return op (x, value); } };
接下来我们仍可以继续使用not1函数将他返回的bool值取反,原理也是类似的,实现很巧妙
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <class Predicate>inline unary_negate<Predicate> not1 (const Predicate& pred) return unary_negate <Predicate>(pred); } template <class Predicate >class unary_negate : unary_function<typename Predicate::argument_type, bool > {protected : Predicate pred; public : explicit unary_negate (const Predicate& x) : pred(x) { bool operator () (const typename Predicate::argument_type&x) const return !pred (x); } };
5.3 C++11 bind 在新版本的C++11中,有新的适配器bind,比之前的更高级。可以绑定函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 using namespace std::placeholders; double my_divide (double x, double y) { return x/y; }auto fn_five = bind (my_divide, 10 , 2 );cout<< fn_five () << endl; auto fn_five = bind (my_divide, _1, 2 );cout<< fn_five (10 ) << endl; auto fn_five = bind (my_divide, _2, _1);cout<< fn_five (10 , 2 ) << endl; auto fn_five = bind <int >(my_divide, _1, _2);cout<< fn_five (10 , 3 )<< endl;
同时也可以绑定函数对象、成员函数甚至成员变量
1 2 3 4 5 6 7 8 9 10 11 12 struct MyPair { double a,b; double multiply () return a*b; } }; MyPair ten_two {10 , 2 }; auto bound_menfn = bind (&MyPair::multiply, _1);cout << bound_memfn (ten_two) << endl; auto bound_memdata = bind (&MyPair::a, ten_two);cout << bound_memdata () <<endl;
5.4 inserter 迭代器适配器 copy在算法中已经写死了,他的复制方式就是给定源的开始和终止目标,然后用覆盖的方式复制到目标位置
但是如果我们希望用插入的方式呢?copy函数不能修改,他就是不断移动指针和赋值的操作
1 2 3 4 5 6 7 list<int > foo = {1 , 2 , 3 , 4 , 5 }; list<int > bar = {10 , 20 , 30 , 40 , 50 }; list<int >iterator it = foo.begin (); advance (it, 3 ); copy (bar.begin (), bar.end (), inserter (foo, it));
下面给出了copy中的核心代码部分
1 2 3 4 5 while (first!=last) { *result = *first; ++result; ++first; }
开发人员非常巧妙的利用了运算符重载,将=运算符重载为insert插入函数,解决了这个问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 template <class Container , class Iterator >inline insert_iterator<Container> insert (Container& x, Iterator i) typedef typename Container::iterator iter; return insert_iterator <Container>(i); } template <class Container >class insert_iterator {protected : Container* container; typename Container::iterator iter; public : typedef output_iterator_tag iterator_category; insert_iterator (Container& x, typename Container::iterator i):container (&x), iter (i) {} insert_iterator<Container>& operator =(const typename Container::value_type& value) { iter = container->insert (iter, value); ++iter; return *this ; } };
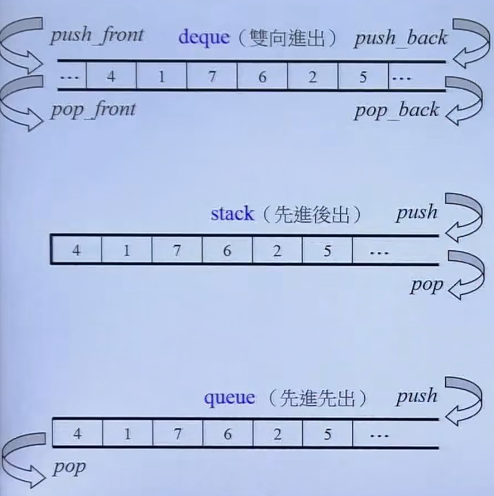
6 array和deque例子
以array作为例子(GNU2.9),该容器的实现中,迭代器 iterator 就是一个普通的指针,接下来进入针对指针的萃取机中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 template <typename _Tp, std::size_t _Nm>struct array { typedef _Tp value_type; typedef _Tp* pointer; typedef value_type* iterator; value_type _M_instance[_Nm ? _Nm : 1 ]; iterator begin () { return iterator (&_M_instance[0 ]); } iterator end () { return iterator (&_M_instance[_Nm]); }}
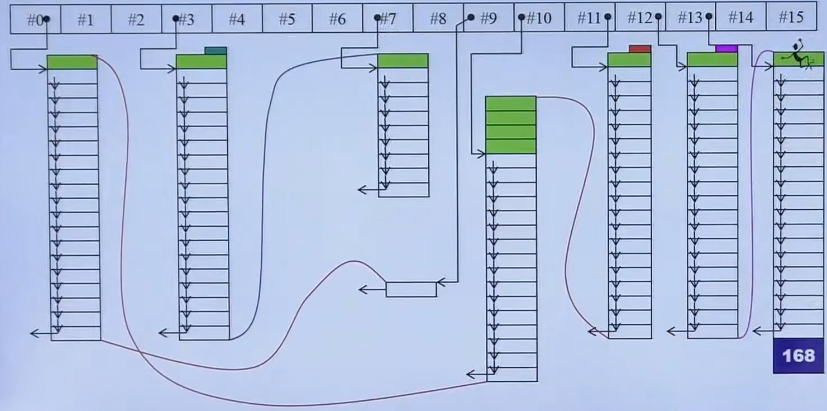
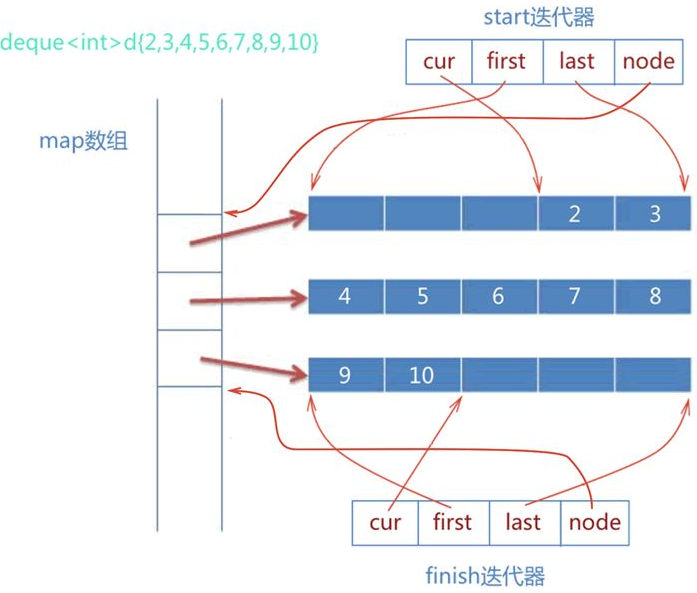
以deque双端队列为例子(GNU2.9),这里的 iterator 有很多复杂的动作,所以需要额外的定义该迭代器类来完成这些动作
deque底层维护了一个map数组,这个数组指向了几个分段数组。deque的迭代器类重写了++、–、*等运算符,并且自动从一个分段数组进入另一个分段数组,制造连续假象
cur:当前遍历的元素
first:当前片段的首地址
last:当前片段的尾地址
node:二级指针,指向map中的指针,该指针指向当前内存地址
map数组扩充时,如从8扩充到16的时候,会把map复制到新的map的中间部分,让左右都有冗余
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 template <class T , class Alloc =alloc, size_t BufSiz=0 > class deque {public : typedef T value_type; typedef __deque_iterator<T, T&, T*, BufSiz> iterator; protected : typedef pointer* map_pointer; protected : iterator start; iterator finish; map_pointer map; size_type map_size; public : iterator begin () { return start;} iterator end () { return finish; } size_type size () const { return finish - start; } }
stack 栈后进先出和 queue 先进先出都是 deque 的部分功能。但注意,stack 和 queue 都是特殊的容器,他们有特殊的性质,所以没有迭代器,也不允许遍历
queue<typename _Tp, typename _Container = deque> 队列可以人为配置第二个部分容器是什么,也就是内存片段使用什么存储因为要调用pop函数,这里如果使用deque或者stack都是可以的,但是如果使用vector、map、set都会有问题(编译可能通过,但是pop()会error,它们没有这种功能)